Product Case Study
Delivering Fortune 200 reliability through Scout-itAI plus Broadcom NetOps.
A Fortune 200 manufacturer modernized service reliability across plants, applications, and networks by pairing Scout itAI’s Event Intelligence Service (EIS) with Broadcom NetOps. Using the patented Reliability Path Index (RPI), agentic AI, and deep integrations, the team translated noisy telemetry into plain-language, executive-ready answers cutting MTTR, shrinking alert fatigue, and aligning IT with business outcomes.
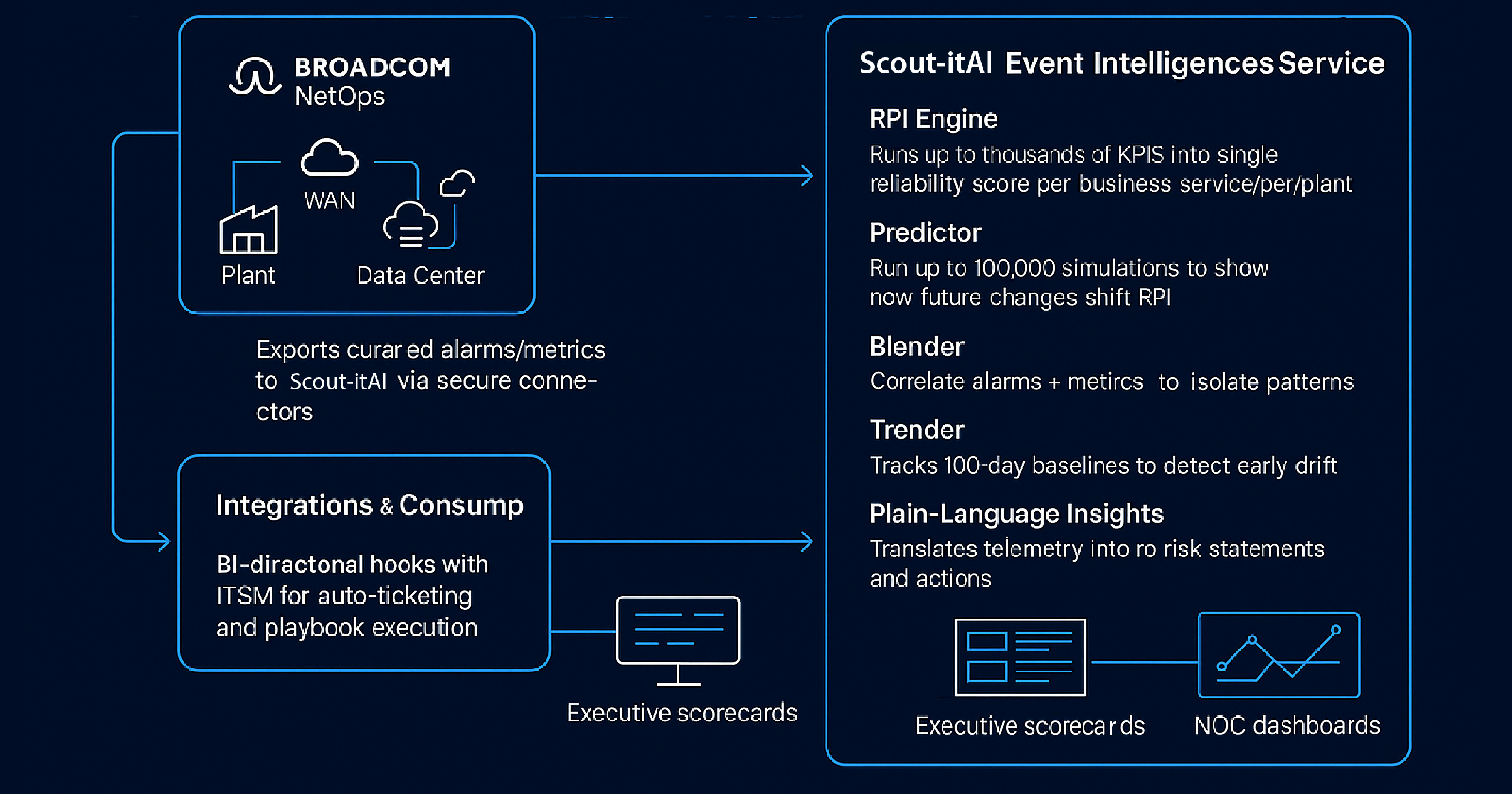
Start with Business Services: Map plants/lines and critical apps to RPI early; don’t boil the ocean.
Govern the Agents: Define safe-action guardrails and rollback paths; measure success per action.
Baseline Before You Tune: Use KAMA-based trends for ~100 days to separate structural issues from noise.
Make It Executive-Ready: Lead with RPI and risk statements; keep metric firehoses behind the scenes.
Forecast to Fund: Use Monte Carlo deltas to justify network and capacity investments with quantified reliability ROI.
Close the Loop: Pipe plain-language recommendations into ITSM playbooks and track outcome KPIs (MTTR, change success rate, RPI lift).
 Simplified Analytics
Simplified Analytics
 Fast Setup
Fast Setup
 Instant Savings
Instant Savings
 24x7 Support
24x7 Support
Stay informed with our latest insights and updates plus industry trends—subscribe to our newsletter today!






