Product Case Study
Scout-itAI cut downtime 45% using unified telemetry and predictive reliability insights.
A large enterprise running core digital services across AWS, on-premises, and SD-WAN needed a way to measure, predict, and improve reliability. Despite having a range of monitoring tools in place, they were still struggling to discover incidents promptly, taking too long to troubleshoot, and leadership was having difficulty obtaining a clear, single view of reliability. They ended up implementing Scout-itAI, a cloud-native Event Intelligence Service that takes complex telemetry data and turns it into plain language insights focused on reliability. Using RPI Score, Predictor (Monte Carlo forecasting), Trender (KAMA baseline), Blender (Six Sigma analysis) and agentic AI automation, they were able to move from a firefighting mindset to proactive reliability operations, which in turn led to a 45% reduction in downtime.
The organisation was struggling with reliability breakdowns that kept on popping up due to a lack of standardised approach across the board:
We had different teams using different tools and metrics to measure health and uptime, which just led to conflicting views and a jumbled mess of reports that nobody really understood.
2. Flood of false alarms and slow root cause analysisWith thousands of alarms and metrics flying in, teams were spending all their time trying to sift through the noise and figure out what was really going on which of course just kept making things worse.
3. Too reactive, not enough proactive operationsMost of the time, issues weren't being picked up until they'd already had an impact on users, and we just couldn't predict how changes to capacity, routing or releases would affect uptime.
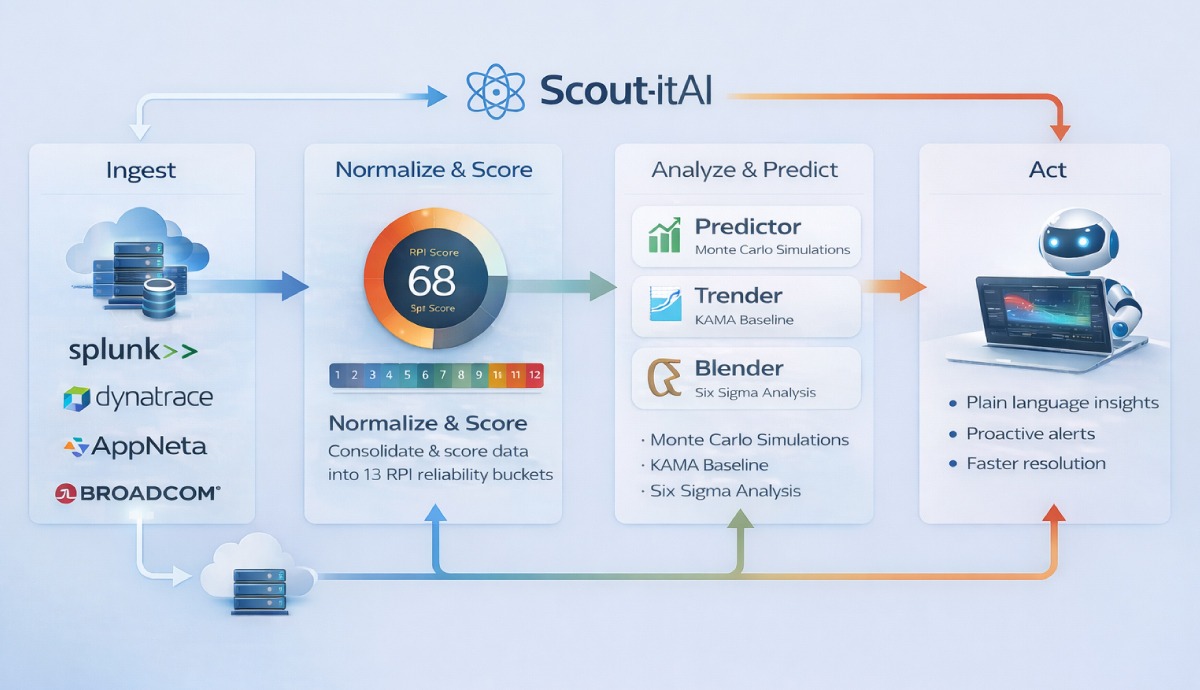
Here's the actual architecture pattern we used to get to a place where we could predict reliability outcomes with Scout-itAI.
After putting it all together, the customer saw some pretty impressive results:
Getting everyone on the same page with a single, standardised reliability score did wonders for eliminating conflicting interpretations from different monitoring tools and making reliability discussions consistent across the board. By cutting back telemetry data to a small set of reliability drivers, we were able to cut down on false alarms and help teams focus on the signals that really mattered - the ones tied to downtime and business impact. And with trend-based detection against a long term baseline, we were able to spot slow degradation earlier on, which of course helped us intervene before the issues escalated. By forecasting reliability impact with simulation, we were able to improve change planning and come up with more confident prioritisation and investment decisions. And plain language, business aligned insights improved executive visibility and cross-functional coordination - which in turn has supported ongoing, measurable reliability improvements.
 Simplified Analytics
Simplified Analytics
 Fast Setup
Fast Setup
 Instant Savings
Instant Savings
 24x7 Support
24x7 Support
Stay informed with our latest insights and updates plus industry trends—subscribe to our newsletter today!






